The last month or so I have been working extensively with Ravello Systems and deploying various solutions on their platform to test new products, conduct study and research and run small proof of concept and demo environments for customers. Of course the Ravello interface itself is as easy as it’s going to get, but sometimes you might want to automate certain features or don’t want your end users to need to log in to yet another portal. Which is where vRealize Automation and the Ravello API come into play.
By using the advanced service designer feature of vRealize automation, we can run workflows from vRealize Orchestrator allowing us to communicate with the REST API of Ravello, and this in turn allows us to provision anything within ravello from the vRealize Automation portal. In this blog we’ll show you a short example on how to deploy applications from a blueprint, but with a bit of imagination anything is possible, from deploying applications from scratch to autoprovisioning elastic IP’s, configuring disk pairs, running auto startup or shutdown tasks, and more.
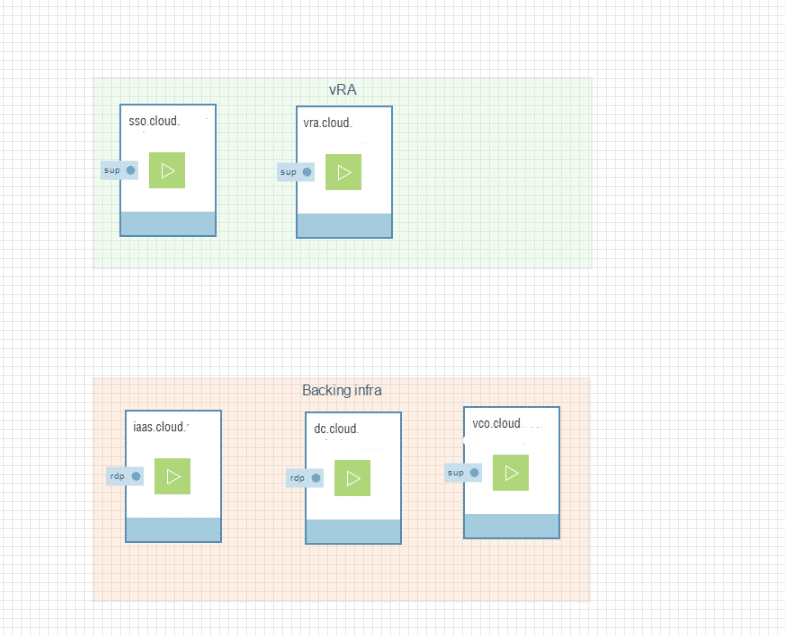
 On the left, you can see our lab infrastructure running in Ravello. In the green group we have the publically accessible infrastructure consisting of the vRealize identity appliance and the vRealize Automation appliance. In the red group we have our IAAS server, Domain controller and Orchestrator server.
On the left, you can see our lab infrastructure running in Ravello. In the green group we have the publically accessible infrastructure consisting of the vRealize identity appliance and the vRealize Automation appliance. In the red group we have our IAAS server, Domain controller and Orchestrator server.
For ease of access I’ve configured the green groups with an elastic IP, then created a CNAME DNS record to point to the DNS record provided by Ravello. This is because vRA is higly dependant on DNS, and using a CNAME record allows me to change the CNAME if i ever need to redeploy any component of the service without needing to do major reconfiguration.
After we’ve deployed the vRealize Automation infrastructure, it’s time to get working on vRealize orchestrator. The first thing we need to do is to add a rest host, using the workflow HTTP-REST/Configuration/Add a REST host. When running this workflow, use https://cloud.ravellosystems.com/api/v1 as the URL, the name can be anything you want. For host Authentication, I’ve used basic authentication with a shared session, but you could potentially modify the workflow to ask users for their ravello credentials during the workflow allowing you to limit access they have to the platform.
After the rest host has been created, it should appear under Administer -> Inventory -> HTTP-REST.  The next thing we need to do is create the following rest operations (through the workflow “Add a REST operation”):
The next thing we need to do is create the following rest operations (through the workflow “Add a REST operation”):
- Get_Blueprints
- Method: GET
- URL: /blueprints
- ContentType: application/json
- Get_blueprint
- Method: GET
- URL: blueprints/{id}
- ContentType: application/json
- Publish_Application
- Method: POST
- URL: /applications/{id}/publish
- ContentType: application/json
- Create_Application
- Method: POST
- URL: /Applications
- ContentType: application/json
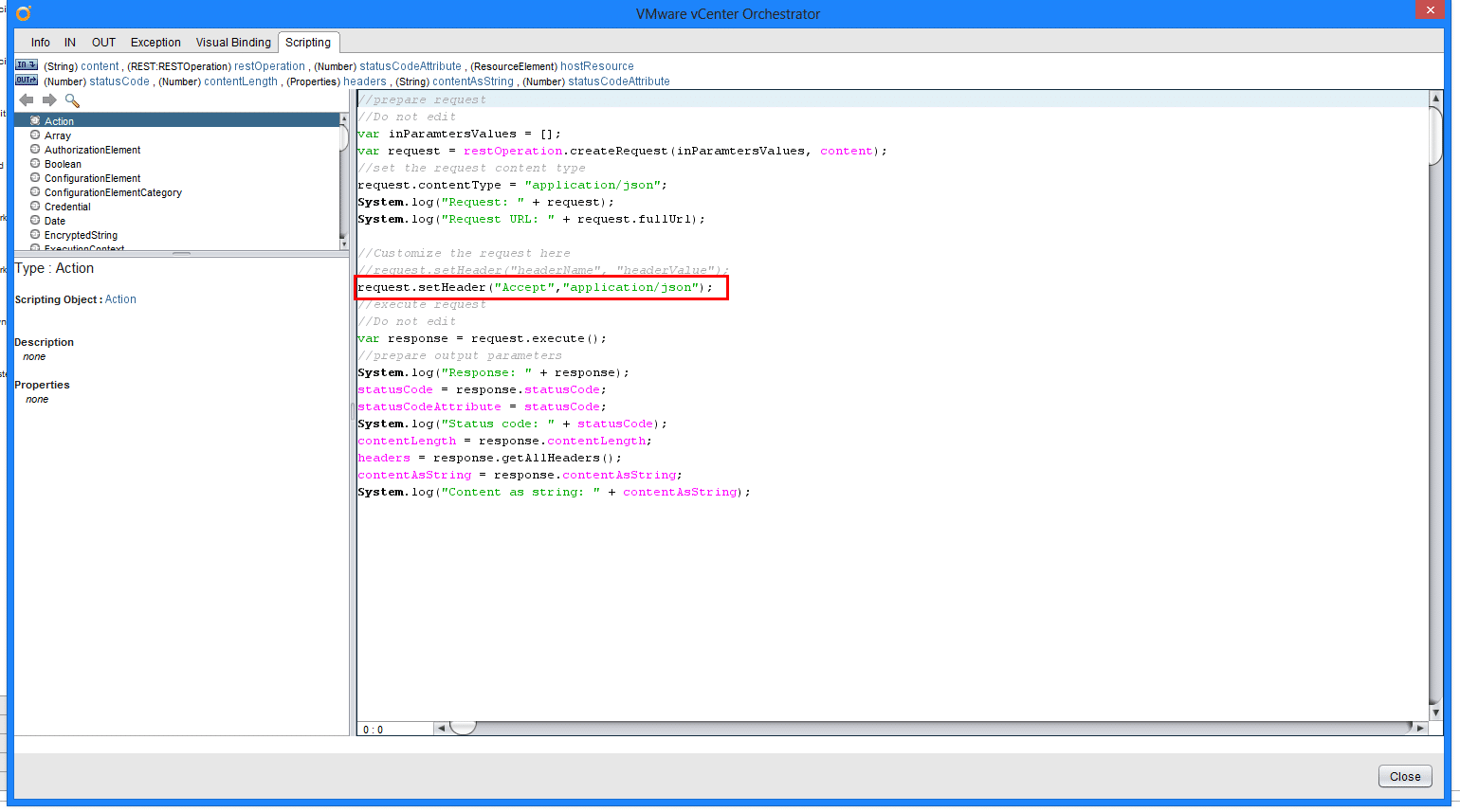 After generating the rest operations, I used the workflow “Generate a new workflow from a rest Operation”. If you are using this in production you are likely better off to build your own workflows based on the examples, but for this demo it’s not a problem to use the pregenerated one. One thing to do is to add the correct headers by adding the line request.setHeader(“Accept”, “application/json”) to all these workflows. By default, ravello will return XML, but since JSON is significantly easier to parse, we’ll ask it to return that.
After generating the rest operations, I used the workflow “Generate a new workflow from a rest Operation”. If you are using this in production you are likely better off to build your own workflows based on the examples, but for this demo it’s not a problem to use the pregenerated one. One thing to do is to add the correct headers by adding the line request.setHeader(“Accept”, “application/json”) to all these workflows. By default, ravello will return XML, but since JSON is significantly easier to parse, we’ll ask it to return that.
With these workflows done, we can focus on our main workflow: “Deploy a ravello blueprint”, which looks as follows:
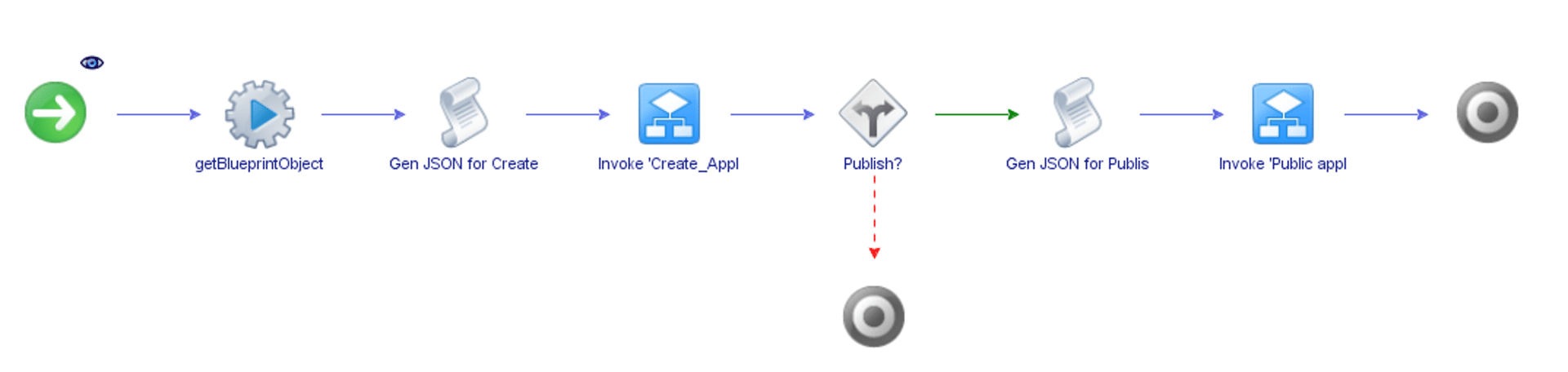
Let’s look at the stages of our workflow: First we run a custom action with the following code:
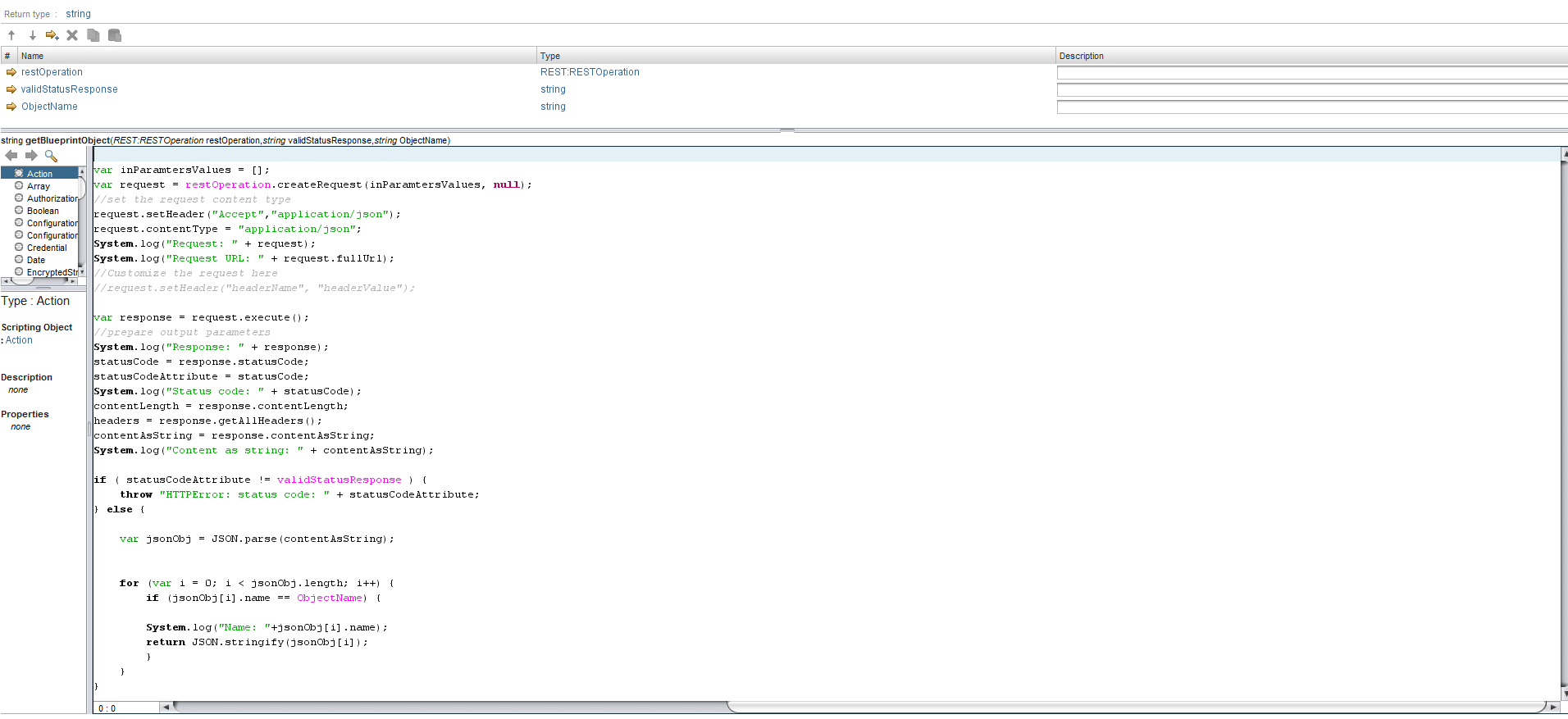
Since the user will be selecting the ravello blueprint name – not the ID – we will need to find the JSON object of the blueprint that matches the selected name first. Fortunately, blueprints are required to have a unique name, so we can safely loop over every blueprint until we find the object that matches our name and return that as a string.
In the next step of the workflow we’ll create a json object that represents our new application. Since we are cloning from a blueprint, we only need to provide the name, the description and the blueprint id. The name and description are entered by the user, the blueprint ID is generated based on the output of our previous action.
var jsonObj = {};
id = JSON.parse(jsonBlueprint).id;
jsonObj = Name;
jsonObj = Description;
jsonObj = id ;
blueprintJsonInput = JSON.stringify(jsonObj);
System.log(blueprintJsonInput);
After generating this code, we’ll run the Invoke ‘Create_application’ that we created earlier, using the json string we just generated as input. After the application has been created, we need to decide if we want to immediately publish it, which is where the decision “Publish?” comes in. If the user selects no, we leave the workflow, if the user selects yes, we generate a JSON to publish the applications, which is done through a scriptable task that looks something like this:
var jsonObj = {};
appId = JSON.parse(jsonApplication).id.toString();
jsonObj = preferredCloud;
jsonObj = preferredRegion;
jsonObj = optimizationLevel ;
jsonObj = startAllVms ;
applicationJsonInput = JSON.stringify(jsonObj);
System.log(appId);
System.log(jsonApplication);
Keep in mind that the id we generate here is not the same id as earlier. The “Invoke Create_Application” workflow outputs the result as a json string containing all the application details, which is then used as input for the “Gen JSON for Publish” scriptable task. In this case, we’re just using it to publish a task, but since this json contains all the application information, one could use this to generate more info in vRA, send information about the lab to a CMDB, kick off a Continuous integration process, charge a user in your billing system, it’s all possible.
Now that we have the workflow, we still need to present this to the user. To do this properly, we’ll use the presentation mode of orchestrator:
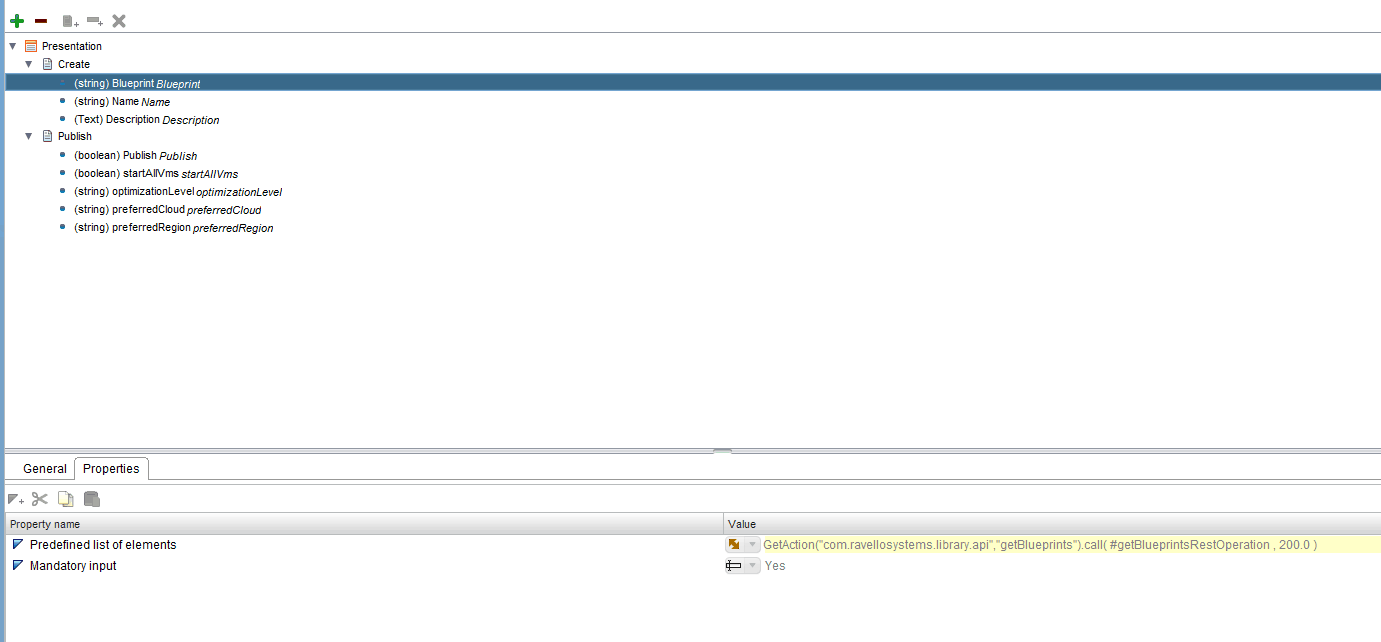 As you can see, for the blueprint selection i am using an action to populate a predefined list of elements. The rest of the dynamic elements (such as the available Clouds and available Regions) are also automatically generated through API actions that get the available deployment options for this specific blueprint.
As you can see, for the blueprint selection i am using an action to populate a predefined list of elements. The rest of the dynamic elements (such as the available Clouds and available Regions) are also automatically generated through API actions that get the available deployment options for this specific blueprint.
The action to retrieve the blueprint names looks as follows:
var inParamtersValues = ;
var blueprintNames = ;
var request = restOperation.createRequest(inParamtersValues, null);
//set the request content type
request.setHeader("Accept","application/json");
request.contentType = "application/json";
System.log("Request: " + request);
System.log("Request URL: " + request.fullUrl);
//Customize the request here
//request.setHeader("headerName", "headerValue");
var response = request.execute();
//prepare output parameters
System.log("Response: " + response);
statusCode = response.statusCode;
statusCodeAttribute = statusCode;
System.log("Status code: " + statusCode);
contentLength = response.contentLength;
headers = response.getAllHeaders();
contentAsString = response.contentAsString;
System.log("Content as string: " + contentAsString);
if ( statusCodeAttribute != validStatusResponse ) {
throw "HTTPError: status code: " + statusCodeAttribute;
} else {
var jsonObj = JSON.parse(contentAsString);
for (var i = 0; i < jsonObj.length; i++) {
System.log("Name: "+jsonObj.name);
blueprintNames.push(jsonObj.name);
}
return blueprintNames;
}
What this action does is run the restOperation get_blueprints that we defined earlier, loops over all the objects in the JSON we get from the API, then pushes the name property of the object into a new array, which we return as an array of strings, allowing the user to select the blueprint by name. Later, we’ll use this name to select the ID of the blueprint we want to provision and feed that into the create_application workflow.
Now, how are we going to present that to the end user?
Log into vRealize Automation with an application architect role and go to the Advanced services -> Service Blueprint tab and add a blueprint. Then, select our new workflow: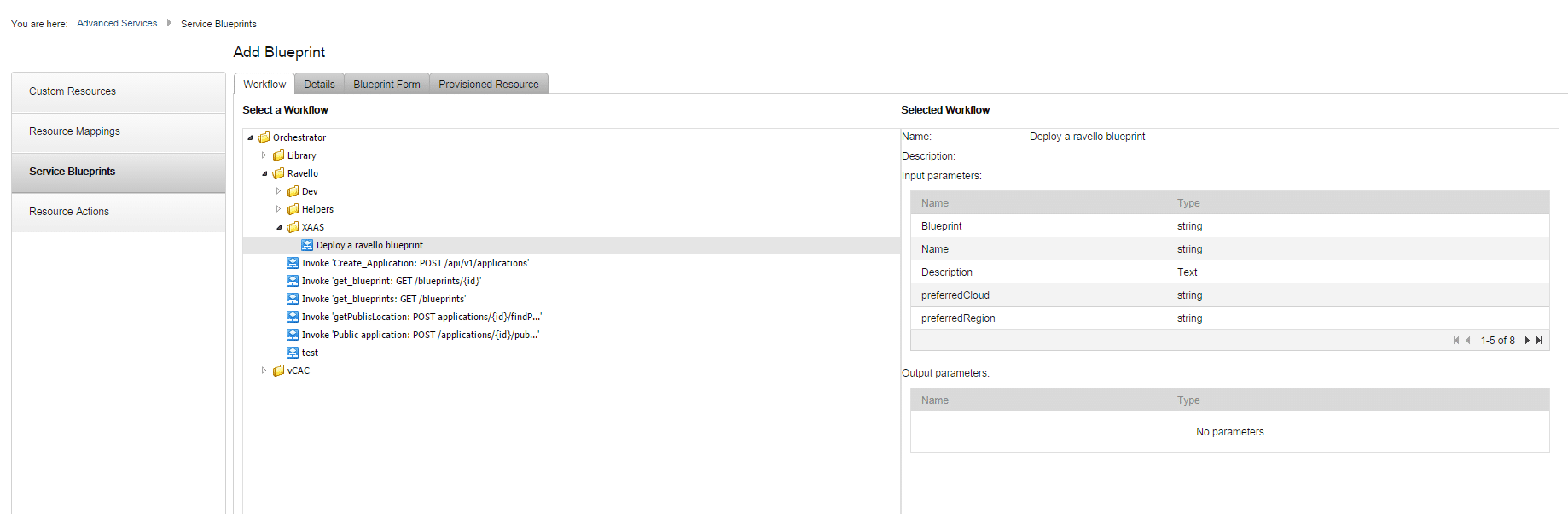
The next pages can all be accepted as default, since we are not using any provisioned resources at the moment. After we’ve assigned the blueprint to a service and given a user an entitlement, the service shows up in the catalog.
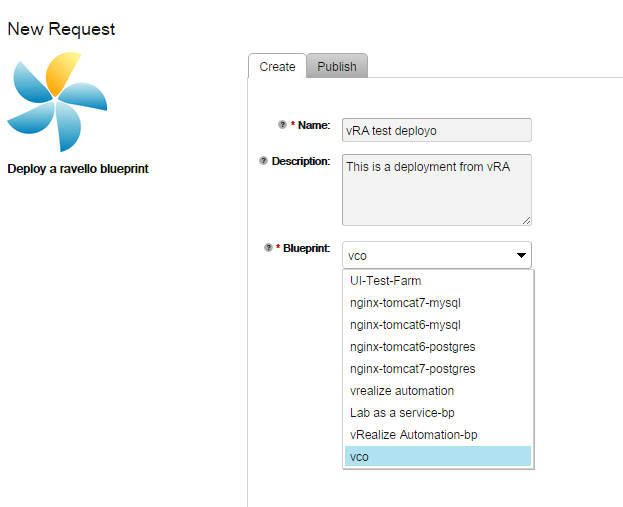 After requesting the resource, we’ll deploy the “vCO” blueprint, which is a very small blueprint I’ve created to test this workflow. As you can see, it’s showing all blueprints that are available to that user. It is in fact also possible to only show blueprints belonging to the organization with a very simple change to the API, but to showcase the API functionality it’s easier to show all blueprints.
After requesting the resource, we’ll deploy the “vCO” blueprint, which is a very small blueprint I’ve created to test this workflow. As you can see, it’s showing all blueprints that are available to that user. It is in fact also possible to only show blueprints belonging to the organization with a very simple change to the API, but to showcase the API functionality it’s easier to show all blueprints.
After accepting the first screen, move on to the “Publish” page. Depending on our selection here, additional options become available. If the user doesn’t decide to publish, we’re done. If we do publish and select cost optimized, the user doesn’t get to select a Cloud and region. 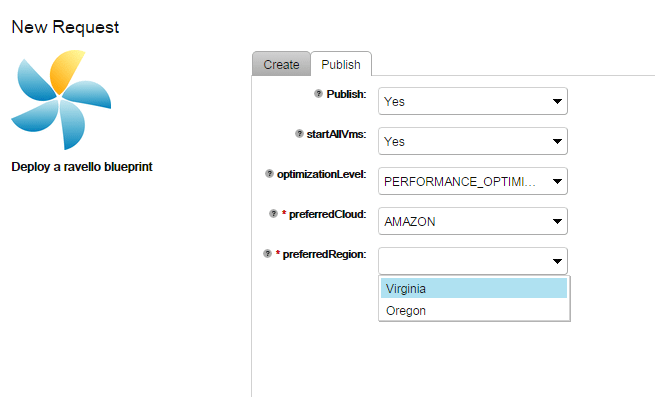 Selecting performance optimized allows us to select a cloud, and then based on that cloud select a region. All this information is gathered as input for the workflow earlier, converted into a JSON string and fed to the ravello API which will execute the commands.
Selecting performance optimized allows us to select a cloud, and then based on that cloud select a region. All this information is gathered as input for the workflow earlier, converted into a JSON string and fed to the ravello API which will execute the commands.
After running the workflow, the ravello interface updates almost directly (and it even includes the accidental typo I made in the request).

Hopefully this blogpost has shown you what can be done through the use of orchestrator, vRealize Automation and the ravello API. While this example is a very simple fire-and-forget type of provisioning, in the future I would like to use Orchestrator’s Dynamictypes to create actually ravello application objects inside vRealize Automation, allowing users to interact with them after provisioning. Examples of this would be deletion of labs, powering on/off, setting rules, sharing labs with other users, connecting to the lab’s virtual IP, etc.
If you would like to talk about the possibilities of Ravello or vRealize Automation or are interested in automating your IT infrastructure, feel free to contact me at srobroek@itq.eu or +31(0)6239007866,